In search of a better file finder
I enjoy learning new tools, so in recent months I have tried Spacemacs,
Emacs, and now Neovim. The editor I used
most often previously was VSCode, and I found
myself missing the command-palette and file finder in Neovim. I have tried fzf.vim,
telescope.nvim, vim-clap, and have looked at ctrlp, command-t, and a few other plugins.
I have also tried including adding the ** glob to vim’s search path. None of these solutions have
met my needs for file finding.
Fuzzy Finding
In my many tests with Neovim file finding plugins, I came to realize that I really don’t like fuzzy finding.
One of the most popular modern command line tools is fzf. It is
a fast way to find a specific file recursively. My problem with fzf is that it often doesn’t find the file I want.
One example where fzf fails is searching for GNUmakefile in Blender’s repository. The file is found, but the first result is
source/blender/makesdna/DNA_fileglobal_types.h, with GNUmakefile being 9 files away.
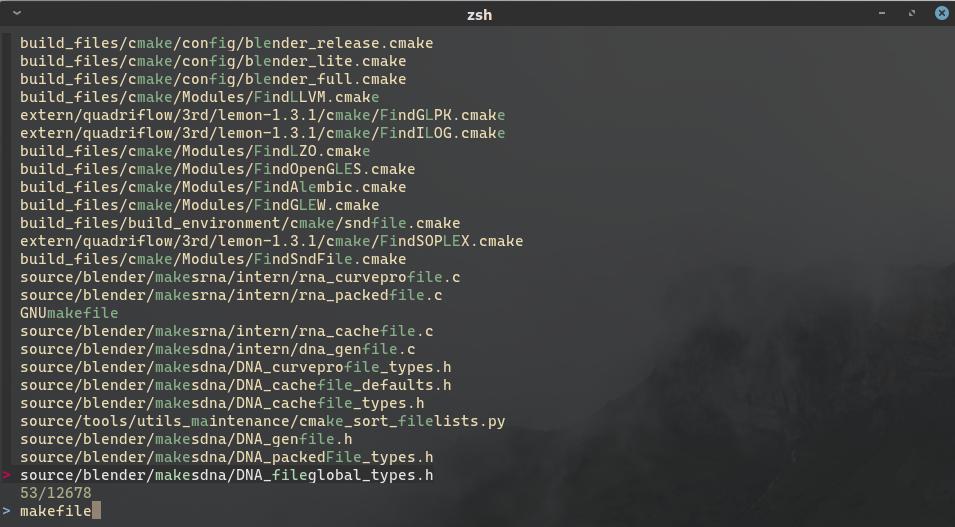
In the above image, typing the string makefile finds one complete match, and many partial matches spread
across the file paths. For example, the substring make is matched with the cmake subdirectory, and the letters
of file are spread across the filename FindGLPK.cmake.
Although I understand why fzf is so popular, the algorithm doesn’t match what I expect from a file finder. This experimentation with text editors led me to think of why fuzzy finding doesn’t work for me, and what I would expect from a better finder. Instead of fuzzy finding, I want to file find.
File Finding
Rather than fuzzy finding, I expect an editor finder to act more like the find or fd commands, matching on the
names of the files rather than the paths. find . -type f -iname "*makefile*" or fd makefile both filter the same
directory as above to the file GNUmakefile.
In thinking of alternative algorithms, I theorized that prioritizing matches on file names would yield the best results. I figured that in the majority of cases, the queried name would be unique among all other file names. If this is most often the case, then it makes sense to optimize the algorithm to match based on the file name, then find ways to tweak the algorithm to improve the results when multiple filenames match.
For example, when working on the Blender Outliner editor in VSCode, a search for “outliner draw” would find the
file outliner_draw.c. This is a case where only one file matches that name. But I have also worked on other projects
where there are many files with the same or very similar names, like __init__.py files in Python packages, or
file.c and file.h pairs. I assumed that the majority of files names would be unique, but I wanted to confirm
my theory.
Data Collection
So I gathered a directory of 30 git repositories. Some were already cloned locally or a personal project, and others were just large projects that came to mind.
I then wrote a Python script to walk through each file in each directory and compute some basic
statistics on each project. Then the results were averaged at the end and a simple ASCII histogram is
printed. The goal is to determine how many files in a project are uniquely named. In the script, I consider
a name to be the name of a file without its extension. Each name that is only found once in the project is
counted as unique. I also considered the case where a name is used twice, but only with a differing extension
(like a .h and a .cpp file with the same name). Finally any other name found twice or more is considered
non-unique.
The script can be found here: https://gist.github.com/natecraddock/c983f0313341f76f39a8dd033a838f6e I also include the full output from each test in the gist.
The results are as follows:
Avg Files: 29568.70
Avg % Unique Files: 60.57%
Avg % Non-unique Files: 39.43%
Avg % Unique Pairs: 13.05%
Avg % Considered Unique: 73.62%
Min % Considered Unique: 12.23%
Max % Considered Unique: 99.63%
x
x
x
x
x
x x
x x xx
xxxx xxx
x xx xxxxxxxxx
--------------------
The histogram represents a plot of the average percent considered unique, and each column represents 5% on a scale from 0 to 100%.
After running this I decided to take a truly random sample using https://randomrepo.com. Assuming this website gives truly random GitHub repositories, and that my script is not biased, these numbers should be more representative. I used randomrepo to select 50 repositories with 2000 stars or more. The results for this second test are:
Avg Files: 1571.00
Avg % Unique Files: 63.69%
Avg % Non-unique Files: 36.31%
Avg % Unique Pairs: 10.11%
Avg % Considered Unique: 73.80%
Min % Considered Unique: 35.82%
Max % Considered Unique: 100.00%
x
x
x
x
xx x x
x xxx xxxx
xx xxxxxxxx
xx x xxxxxxxx
xxxxxxxxxxxxx
--------------------
Empirical Analysis
Both tests report an average of around 73% for amount of unique file names in a project. The “% Considered Unique” is the sum of the percentage of unique files and percentage of paired files (differ only in extension). Considering only the truly unique file names the average is between 60 and 63 percent, which is still a majority of files.
With these results I am confident in my original theory that the majority of filenames are unique in a project. So my file finding algorithm should be optimized for this case. The data from these repositories can also be used to determine strategies for finding filenames that are not unique.
Differing Extensions
The first case of non-unique filenames is simple. From the data around 10% of filenames were considered a unique pair where only the extensions differ between the two files. In this case the simple solution is to match against the file name and extension when filtering the list. This also extends to any case of a filename with three or more differing extensions.
Differing Filepaths
This is a more complex case. There are some cases like in Python where each package may have an __init__.py file,
for example a ui/__init__.py and a config/__init__.py file. In many of these cases the directory name immediately
preceding the filename is enough to distinguish the filename from others in the project.
Sometimes though, the paths preceding two files with the same name are similar for many levels, so this search up the
directory tree should not be limited to the first level. For example, in Blender and other CMake projects there are many
CMakeLists.txt files. One tricky pairing is source/blender/makesdna/intern/CMakeLists.txt and
source/blender/makesrna/intern/CMakeLists.txt which differ in only a single character in the filepath.
Although the average for unique filenames was around 73%, there were multiple projects with 50% or less. One such project was amazeui, with only 36.15% considered unique, even considering paired filenames. Running my script on a single path prints out more verbose information on that project, and the output shows why this project ranked so low.
paragraph
widget/paragraph/src/paragraph.js
widget/paragraph/src/paragraph.less
widget/paragraph/src/paragraph.hbs
This is just one of many folders of widgets that contain three or more similar files. This case is easily handled by searching for the exact file type desired.
Other directories are slightly more complex. There are many docs files with the exact same name and only slightly different paths depending on the documentation language.
popover
docs/javascript/popover.md
docs/en/javascript/popover.md
Because the paths are nearly identical, a search query would need to include the string “en” to differentiate between the two popover.md files.
Next Step
This exercise has been a very fun and informative process, and after looking through the results, I feel that my file name focused design is validated. Once I have written and tested an algorithm I will share more, hopefully detailing a successful outcome!